

 I was fortunate enough to attend the Brocade Analyst and Technology Day event back in September at their corporate headquarters in California. I have a dual interest in Brocade as I follow them from a general technology perspective and I also happen to work for a Brocade reseller.
I was fortunate enough to attend the Brocade Analyst and Technology Day event back in September at their corporate headquarters in California. I have a dual interest in Brocade as I follow them from a general technology perspective and I also happen to work for a Brocade reseller.
This event was centered around the data center and the main attraction, at least for me, was the unveiling of the 8770 VDX switch. This was a big addition to their already flourishing VDX line of switches. They discussed some other things during that event like their involvement with OpenStack as well as the advantages of using their ADX line of ADC’s/load balancers.
Another Switch?
Yes. Another switch. Not just any switch though. This is not old Foundry gear or old technology. This is a platform that has been built with the future in mind. I say that for a few reasons.
1. Each slot has up to 4Tbps capacity.
2. 8 slots for power supplies at 3000W each. You don’t need more than 3 to power the switch today.
3. 100Gig ready.
4. 3.6 microseconds any-to-any port latency.
I took a few pictures of this switch. It looks very heavy. I poked and prodded it without actually pulling line cards out and it seemed pretty sturdy. Every knob or lever seemed to be durable metal.


Of particular note are the humongous fans on the back of the chassis.

Here is a close up of the intake slot on the front. Hard to believe this little guy sucks in all the cold air.

This chassis can support up to 8 3000W power supplies. You won’t need 8 of them for years to come. However, the capability is there so that the chassis can be used as the line cards get upgraded in the future.

A close up shot of all 6 fabric modules.
Okay, so that isn’t impressing you is it? If you want more speeds and feeds regarding the 8770 VDX platform, read Greg Ferro’s post here. He also has some pictures. In fact, you can see me in the front of the switch, gut and all, taking my pictures while he was taking the picture of the fans in the back.
But Wait! There’s more…….
There was one feature on the 8770 that I thought was extremely interesting. Load balancing across multiple inter-switch links on a per frame basis.
Before I go into more detail on that, allow me to explain how load balancing across multiple links typically works. I’m aware that different vendors use different terms. You’ll see me do the same. No matter the term being used, we are talking about aggregating multiple physical links connecting switches to each other into a single logical interface.
Link Balancing Basics
Traffic is balanced across redundant or bonded inter-switch links using a few different criteria, but the major ones I am aware of are the following:
Source MAC Address
Destination MAC Address
Source IP Address
Destination IP Address
Source TCP/UDP Port
Destination TCP/UDP Port
This will vary according to the vendor and intelligence of the platform. Some switches might only support source/dest MAC address to determine which link to use. One thing should stand out with the above list though. The link chosen is going to be flow based. The more unique you can get, the better. That probably means you are going to favor using the TCP/UDP ports if your switch supports it.
Considering that an entire flow goes across a single link, you can see how this could result in uneven load. A 4 link bond between 2 switches could result in 1 link getting high usage while the other 3 links have much less traffic on them. In reality, if you were to logically group 4 x 10Gbps interfaces together, you wouldn’t have a single true 40Gbps interface. You would have 4 x 10Gbps interfaces that are 1 logical interface and can failover to each other should a link go down.
Reference the drawing below. I used the term “trunk group” to represent the logical interface created by combining 2 or more physical links together. That’s the term Brocade uses. For Cisco enthusiasts, that would be a port-channel interface. 4 x 10Gbps interfaces are bonded together using LACP or some other mechanism to present themselves as a single logical interface. The various colored rectangles coming into the switch represent individual flows. Notice the red flow going into port 2 while the purple and orange flows go into ports 4 and 5. If each rectangle is a single Ethernet frame, then you can see the imbalance. In the case of port 7, it has 2 different flows going across. This is a very basic representation of link balancing, but it should give you the general idea. If you want more info on this from a Cisco switch perspective, read Ethan Banks’ post from 2010 here.
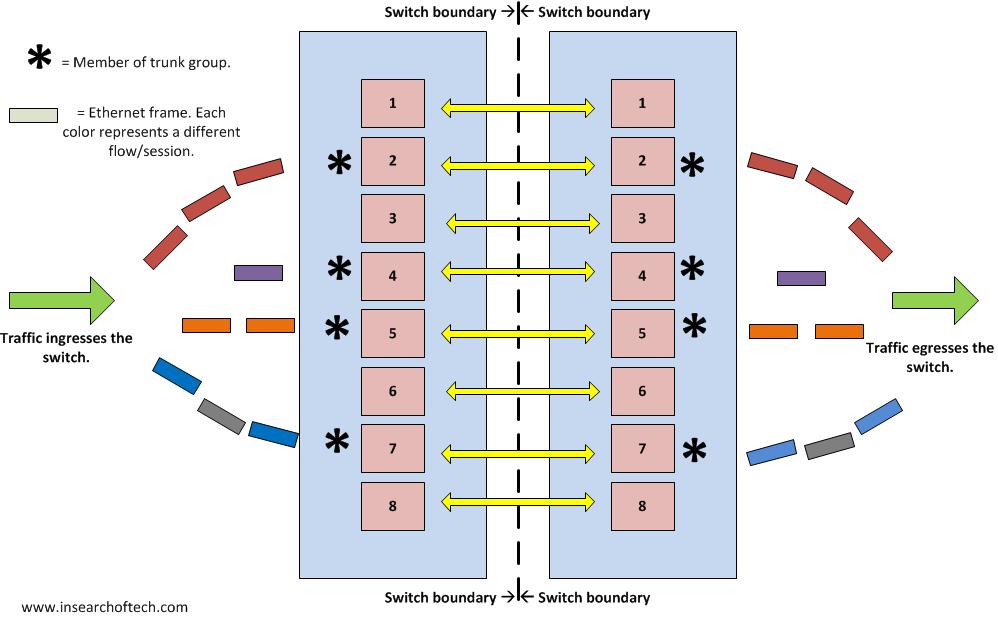
A Better Way
The neatest thing I saw regarding the 8770 was the layer 1 link bonding. That’s right. Using layer 1 to merge links together. They called it “frame spraying”, although it is referenced in a slide deck from the event as “frame striping”. In any event, they are able to balance traffic across all ports in a trunk group on a per frame basis. That’s as close as you are going to get to ideal load balancing. You don’t have to modify a hashing algorithm to make this happen. It does it automatically. The only caveat is that all ports in the trunk group have to be tied to the same port ASIC and it is limited to 8 ports in a trunk group. Using 10Gig interfaces, that’s an 80Gbps trunk group that can exist between two 8770’s. I should point out that this existed prior to the 8770. I just wasn’t paying close enough attention to it until the 8770.
The diagram below shows traffic flow when using Brocade’s frame spraying technology. In this example, I used 4 x 10Gbps interfaces to make 1 logical 40Gbps connection between 2 switches. You can see that each frame is sent across the 4 links in a round robin fashion.
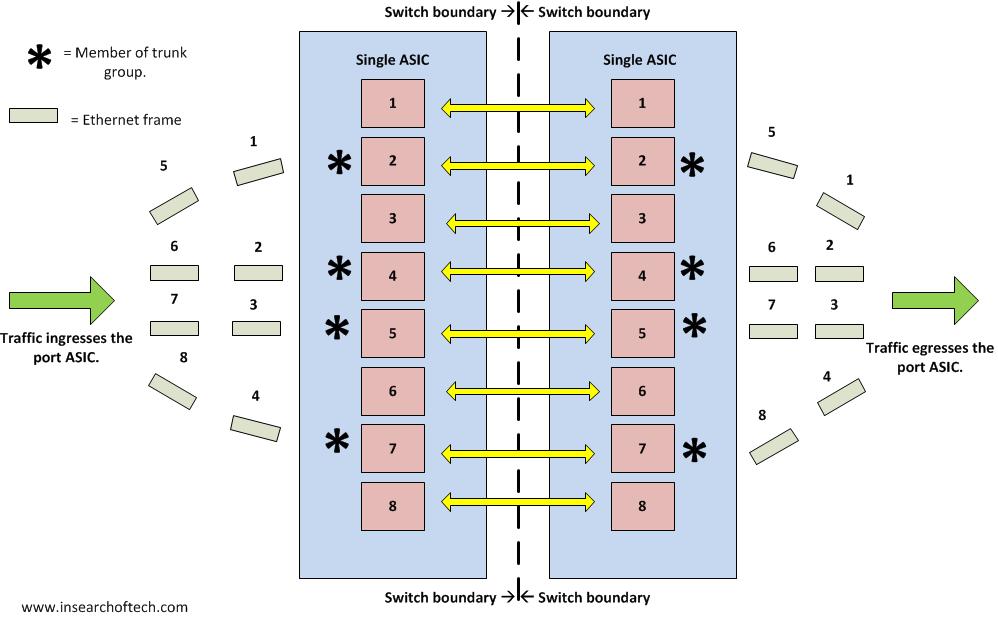
How Does It Work?
Unfortunately, I have to speculate on how they are doing this. Brocade won’t actually tell you. Not that there aren’t hints of course. Ivan Pepelnjak wondered the same thing and mentioned in his post about Brocade’s VCS fabric load balancing that the answer lies in the patents. Brocade is already doing something similar to this in their Fibre Channel hardware, so naturally it was easy for them to just port it over to the Ethernet side of things.
I read through several of those patents. All I got was a headache and more confusion. It was better than reading RFCs though. I still don’t know for sure how it works, but I am going to take a guess.
The fact that all members of the trunk group have to be tied to the same ASIC should help us speculate as to what is going on. My guess is that some sort of low level probe or primitive goes out each port. The neighbor switch is doing the same thing. When these probes are received, the ASICs can very quickly figure out which ports are talking to the same ASIC on the other end. Some sort of tag might be used saying: “I am port X, tied to ASIC X, and tied to switch X.” I would probably compare this to a lower level form of LLDP, FDP, or CDP. I could be COMPLETELY wrong on this, but we’ll never really know unless someone can find the hidden method by reading a bunch of patents or Brocade decides to publish the method themselves.
Closing Thoughts
I could have focused on other things that I saw at the Brocade tech day event, but chose to focus on the “frame spray” feature instead due to the “neat” factor of it. This has significant real world application. I was recently involved in a network congestion issue around FCoE performance. The fix action was to change the algorithm that the switch used for load balancing across bonded links to another switch from the default source-destination MAC to the more granular TCP/UDP port. Performance increased dramatically after that change. Imagine if that wasn’t an issue at all and near perfect load balancing was occurring? With Brocade’s VCS technology, which is a part of their VDX line of switches, you don’t have to worry about it as long as you plan out your physical connections properly.
Here are a few posts from others who were at the Brocade event with me:
Brocade Tech Day – Data Centers Made Simple – Tom Hollingsworth